Understanding RNN, LSTM, and Transformers
Understanding RNN, LSTM, and Transformers: A Deep Dive
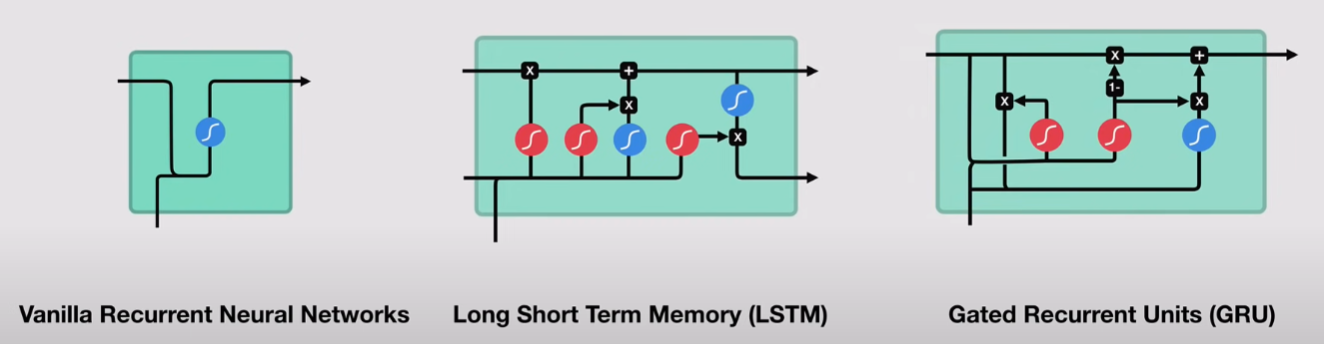
1. Recurrent Neural Networks (RNNs)
-
What is it? RNNs are a type of neural network designed for sequence data. They are commonly used in tasks like time series forecasting, language modeling, and speech recognition, where the order of data is important.
-
How it works: RNNs have a "memory" that captures information from previous steps in a sequence. This is achieved by looping the output of a layer back into itself, allowing the network to maintain a hidden state that evolves as it processes input sequentially.
-
At each time step, the RNN takes the current input and the previous hidden state to produce the current hidden state.
-
The hidden state is updated using a formula like:
where is the hidden state at time , is the input at , and , , are learnable parameters.
-
-
Drawbacks:
- Vanishing/Exploding Gradient Problem: RNNs struggle to capture long-term dependencies because gradients can diminish or blow up during backpropagation.
- Sequential Processing: Computation cannot be parallelized, making training slow.
2. Long Short-Term Memory (LSTM)
-
What is it? LSTMs are a specialized type of RNN designed to address the limitations of traditional RNNs, particularly the vanishing gradient problem. They are effective at capturing long-term dependencies in sequence data.
-
How it works: LSTMs introduce a more complex architecture with gates to control the flow of information:
- Forget Gate: Decides which information from the previous state should be discarded.
- Input Gate: Determines which new information should be added to the cell state.
- Cell State: A memory cell that carries information across time steps with minimal modification.
- Output Gate: Decides what part of the cell state should be output at the current time step.
The equations for LSTM gates:
- , , are forget, input, and output gates respectively.
- is the cell state.
-
Drawbacks:
- Complex Architecture: LSTMs are computationally expensive due to their gate mechanisms.
- Sequential Processing: Like RNNs, LSTMs process data sequentially, making training slow for long sequences.
3. Transformer
-
What is it? Transformers are a deep learning architecture that replaces RNNs/LSTMs for sequential data tasks. Introduced in the paper "Attention Is All You Need," Transformers excel in parallel processing and capturing long-range dependencies efficiently.
-
How it works: The Transformer relies entirely on self-attention mechanisms and eliminates the need for recurrence.
-
Self-Attention: For each input, the model calculates its relationship with all other inputs in the sequence to determine what to focus on.
where (queries), (keys), and (values) are derived from the input using learned weights.
-
Positional Encoding: Since Transformers lack recurrence, positional encodings are added to inputs to capture the order of the sequence.
-
Encoder-Decoder Architecture:
- Encoder: Processes input data and encodes it into representations.
- Decoder: Uses the encoder’s output and generates the desired output (e.g., a translated sentence).
-
-
Advantages:
- Parallel Processing: Unlike RNNs/LSTMs, Transformers process the entire sequence at once, enabling faster training.
- Better Long-Range Dependency Capture: The self-attention mechanism allows Transformers to focus on relationships between any two tokens in the sequence.
-
Drawbacks:
- Resource Intensive: The quadratic complexity of self-attention makes Transformers computationally expensive for very long sequences.
- Data-Hungry: Transformers require large datasets to achieve good performance.
3.1. Why the Next One Was Needed
-
From RNN to LSTM:
- RNNs suffered from the vanishing gradient problem, making them ineffective for long-term dependencies.
- LSTMs introduced gates to manage memory and flow of information, effectively solving this problem.
-
From LSTM to Transformer:
- LSTMs were slow to train due to sequential processing.
- Transformers introduced parallel processing and self-attention, enabling faster training and better performance on long-range dependencies.
3.2. Key Takeaways
| Feature | RNN | LSTM | Transformer |
|---|---|---|---|
| Handles Long-Term Dependencies | Limited | Yes | Yes |
| Parallel Processing | No | No | Yes |
| Vanishing Gradient Problem | Yes | No | No |
| Training Speed | Slow | Slower than RNN | Fast |
| Computational Complexity | Low | Moderate | High |